| 结对使用的Github项目地址 | https://github.com/YFDreamChaser/WordCount.git |
| 结对伙伴作业地址 | https://www.cnblogs.com/jcahsy/p/10631609.html |
| 作业地址 | https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass2/homework/2879 |
一、结对过程
金城在小组群里找搭档,然后我便给他说我跟他一起吧,于是结对成功。下图是我们结对编程的照片:

我主要设计代码结构,编写统计单词类和扩展功能这个些模块,然后金城负责排序Topn模块,最后我把代码功能合并,金城进行测试。
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | 270 | 200 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 30 |
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 (和同事审核设计文档) | ||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 60 | 30 |
| · Coding | · 具体编码 | 180 | 300 |
| · Code Review | · 代码复审 | 20 | 25 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 10 | 10 |
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 | 550 | 670 |
三、解题思路描述
我们想的思路就是先把这个文章清洗一遍,清洗的过程中就把字符个数给统计出来,把不规则的符号变成空格,把汉字去除,最终结果便是所有单词之间用一个空格隔开。代码如下 清洗完成之后,再来分析这篇文章中的单词数,我们采用分组聚合的思想,相同的单词分为一组,然后分别聚合。代码如下 这样就获一篇文章中所有单词数量分别是多少,然后再通过对单词数量的排序 把前n的单词输出 。
既然我们定义这样的思路,那么我们就要会C#的IO流,以及C#中的Dictionary,以及C#中排序用的比较器,于是我们就得查关于这个的资料。
四、设计实现过程
我们得想法需要有3个类 第一个是word类,用于封装单词内容以及单词个数两个属性,要实现IComparable比较器接口。 第二个是WordCount主体类,里面有多个方法,OpenFile, Analyze,Topn以及PrintToFile方法。以及一个测试类。
OpenFile方法实现字符的统计,以及清洗文本内容,返回一个字符串供其他函数调用。
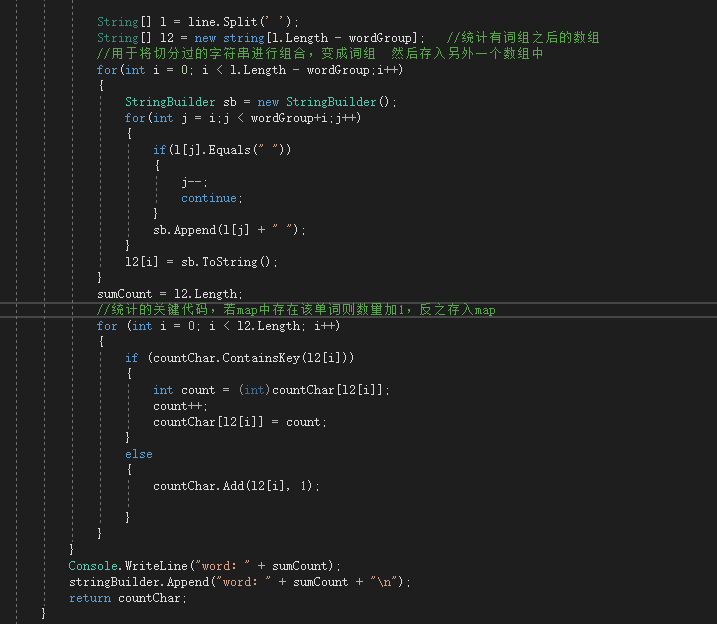
Analyze方法接收OpenFile清洗过后的文本内容(即字符串),然后对单词进行分组聚合,返回Dictionary
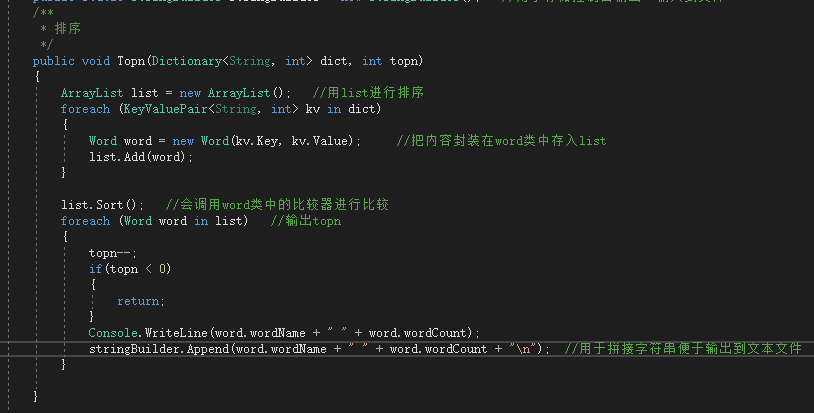
Topn方法接收Analyze返回的Dictionary,利用word类的比较器进行排序。输出最大的前n个单词及其数目。
PrintToFile方法实现将控制台打印的内容也同时写入到文本。
五、代码规范
1.各个功能模块都写上相应的注释
2.注意缩进和括号的层次感
3.类名和方法首字母大写,意义用英语不用拼音,两个不同英文之间用大写
互审时发现的问题:我个人习惯问题,代码注释量太少了,结对伙伴看不懂,于是我便加上了相应应该有的注释。
六、性能分析

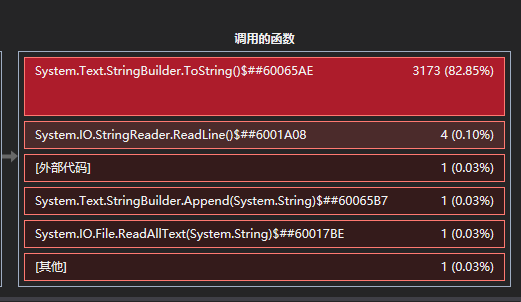
附上代码截图
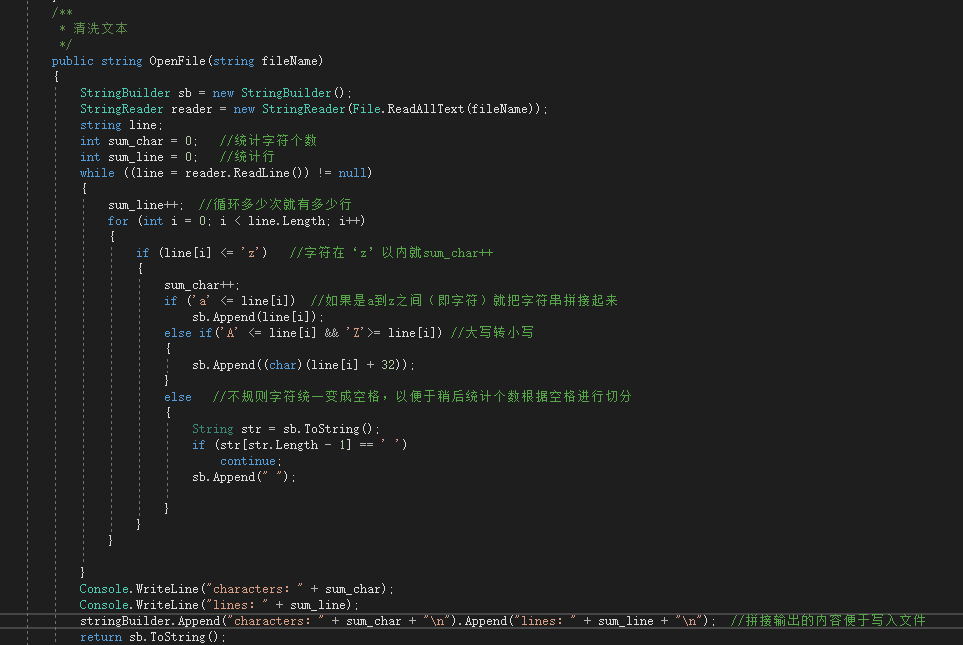
经过效能分析发现OpenFile清洗函数最占用时间。原因在于对于非规格字符的清洗比较困难,遇到了好几个bug,特别是英文文章中逗号和空格是连在一起的,如果两个同时清洗为空格那就是两个空格,不方便之后的切分。于是我采用的一个笨方法,就是把清洗过的文本存入stringbuilder中,然后赋值给一个string,当string的末尾是空格的时候就不执行拼接空格。这样就实现了只会单词之间只会有一个空格。这种方法很笨,但我没想出还有什么好方法。
七、代码说明
思路已经在以上说过了。下面附上几个关键代码,注释已经说明实现思路。
分析文本内容
排序内容
输入到文本文件

这里是定义了一个全局的stringbuilder 存储输出到控制台的内容。然后输入到文本文件。
运行结果展示
小文章


最后的两行是排序结果,核对了下,完全正确。
一篇文章复制多次进行的结果输出
①
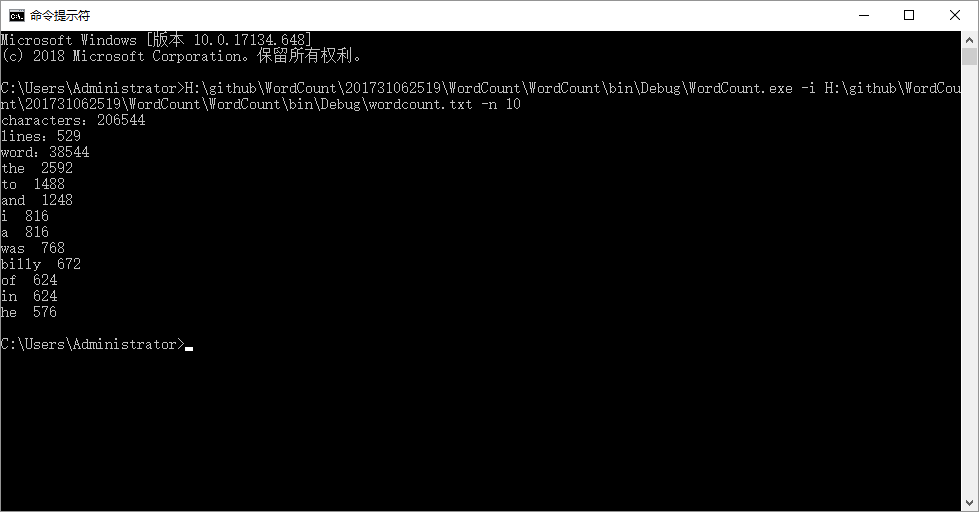
②
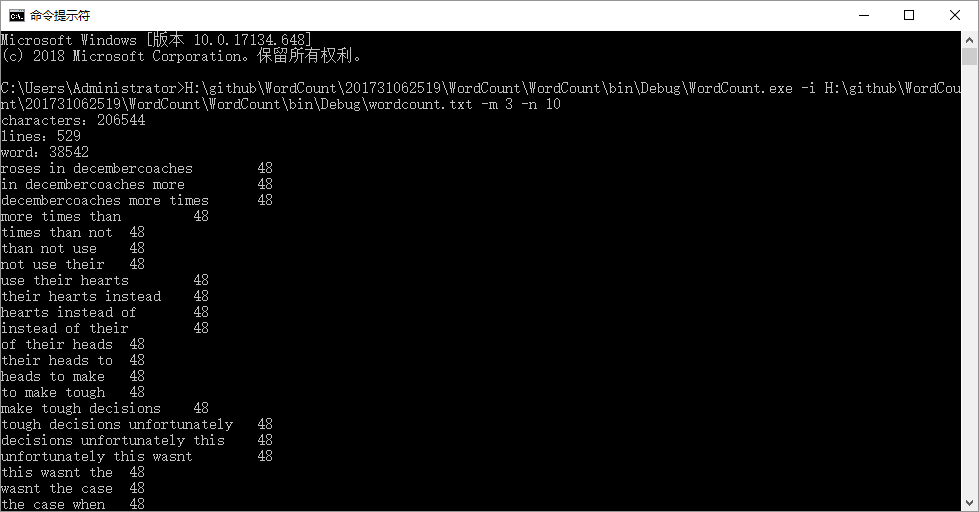
运行底部的top10
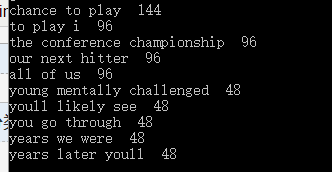
④
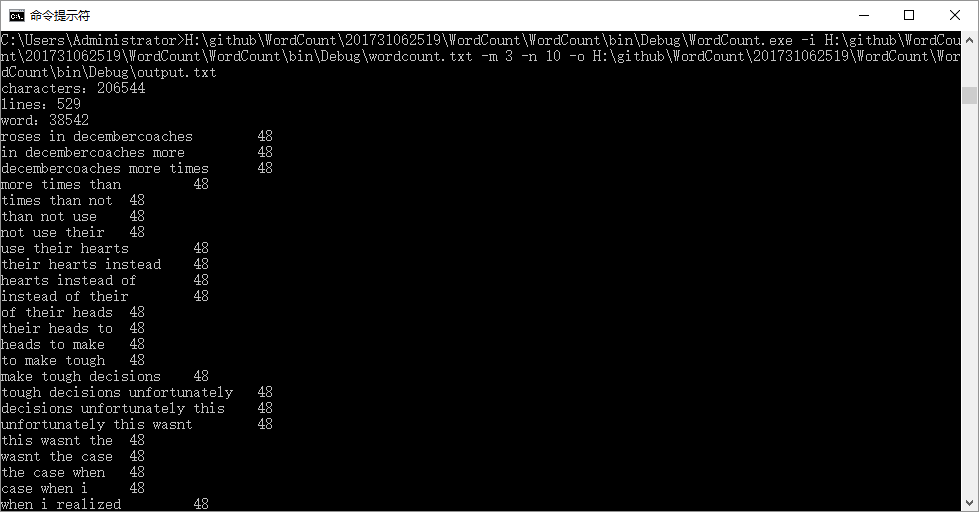
输出到文本的内容


八、心得
确实是1+1>2,两个人在一起合作可以很快的发现问题,并且能明白自己哪里不足,可很快进行改正。最重要的还是一开始如果有个正确架构,便能做出合理的分工,然后能有事半功倍的效果。